

Heute möchte ich euch eine einfache Datenstruktur vorstellen, die für sich genommen sehr simple ist, die aber zur Lösung unterschiedlicher Probleme herangezogen werden kann: Burkhard-Keller Bäume.
Ein BK-Baum ist eine Datenstruktur, die es erlaubt Daten, die über eine Metrik verglichen werden können (also Teil eines metrischen Raumes sind) zu durchsuchen. BK-Bäume können eingesetzt werden, wenn zu einem Suchelement alle diesem ähnlichen Daten gefunden werden sollen.
Hierfür muss das Entfernungsmaß (d) lediglich die folgenden beiden Anforderungen einer Metrik erfüllen:
- d(x,y) = d(y,x) | Symmetrie
- d(x,y) <= d(x,z) + d(z,y) | Dreiecksungleichung
Um jetzt nicht zu mathematisch zu werden suchen wir uns gleich ein Problem mit passender Metrik aus: Wortkorrektur mittels der Levenshtein-Distanz.
Die Levenshtein-Distanz zwischen zwei Worten ist die minimale Zahl an Änderungen (Zeichen einfügen, ersetzen oder entfernen), die nötig sind, um ein Wort in ein anders zu transformieren. In der Literatur ist nachzulesen, dass es sich hierbei um eine Metrik handelt. Beginnen wir nun unser Problem zu beschreiben:
Wir haben ein großes Wörterbuch mit Vorschlägen, die einem Nutzer des Systems gemacht werden sollen in Abhängigkeit seiner Eingabe. Als kleinen Beispiels nehmen wir ein Wörterbuch mit den Worten "hund", "katze", "bunt", "tatze" und "hase". Gibt ein Benutzer nun das Wort "katz" ein, so würden wir gerne das Wort "katze" vorschlagen.
Hierzu legen wir das Wörterbuch als BK-Baum ab. Als Wurzel setzen wir ein beliebiges Wort aus unserem Wörterbuch, beispielsweise "hund"
Für jedes neue Wort, das wir Einfügen berechnen wir den Abstand zur Wurzel. Existiert bereits eine Kante, die mit dem errechneten Abstand markiert ist, so wiederhole das Verfahren mit dem Knoten hinter dieser Kante als neue Wurzel. Existiert eine solche Kante nicht, so erzeuge ein neues Blatt mit dem Wort und markiere die neue Kante mit dem Abstand zum Knoten.
Wir verfahren mit allen Worten und erhalten den folgenden Baum:
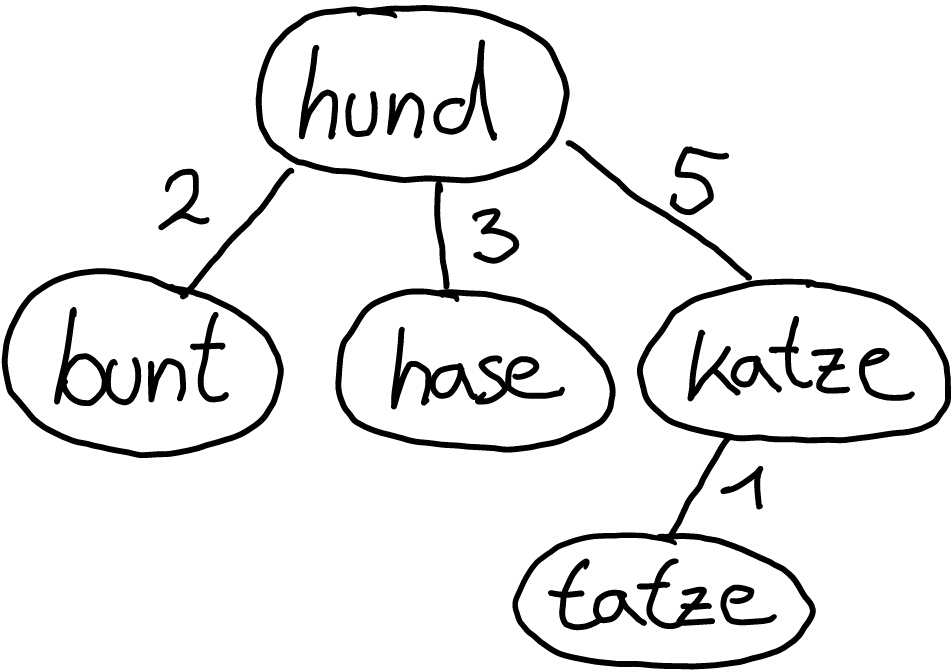
Um nun nach ähnlichen Worten zu einem gegebenen zu suchen müssen nur alle Knoten besucht werden, die einen Abstand zwischen d0+i und d0-i haben, wobei d0 der Abstand zwischen dem aktuell betrachteten Knoten und dem zu suchenden Wort ist und i die maximale Anzahl an Unterschieden zwischen dem zu suchenden Wort und den Einträgen im Wörterbuch darstellt. Jeder Knoten, der selbst eine Distanz zum Suchwort von <= i hat wird natürlich als Ergebnis zurückgegeben.
Wollen wir also alle Worte finden, die sich um maximal eine Änderungen Unterscheiden so starten wir mit i=1.
Wir beginnen an der Wurzel und durchlaufen alle passenden Kanten:
d(hund,katz) = 4 somit müssen wir alle Knoten durchsuchen die eine Distanz zwischen 3 und 5 zum Wort "hund" haben:
Also "hase und "katze".
Wir wiederholen das Verfahren an jedem Knoten
d(hase,katz) = 3 (zu groß um als Ergebnis zu gelten und der Knoten hat keine Kinder => kein Treffer mehr möglich)
d(katze, katz) = 1 (Treffer! Außerdem ist das Kind "tatze" ein weiterer Kandidat)
Wir führen die Suche für "tatze" durch:
d(tatze, katz) = 2 (zu groß und der Knoten hat keine Kinder => kein Treffer)
Somit haben wir alle Wörter mit Maximalabstand 1 gefunden: "katze"
Sofort fällt auf: bei dem kleinen Beispiel haben wir nicht viel gespart (nur "bunt" wurde nicht verglichen). Für große Lexika ist die Einsparung aber erheblich. Wichtig hierbei ist allerdings der "Suchradius" i. Für große Werte von i degeneriert das Verfahren schnell zu einer vollständigen Suche im Baum.
Nichts desto trotz ist das gezeigte Verfahren sehr einfach zu implementieren und kann bereits den entscheidenden Geschwindigkeitsvorteil bringen. Wichtig hierbei ist natürlich: Das Verfahren funktioniert für alle Metrischen Räume und kann somit theoretisch auch zum finden ähnlicher Bilder zu einem Referenzbild genommen werden (mittels Hamming-Distanz von phash).
Neben BK-Bäumen gibt es natürlich eine große Menge spezialisierter Datenstrukturen und Algorithmen, die effizienter arbeiten - vielleicht picken wir uns für das nächste mal ja einen solchen raus)